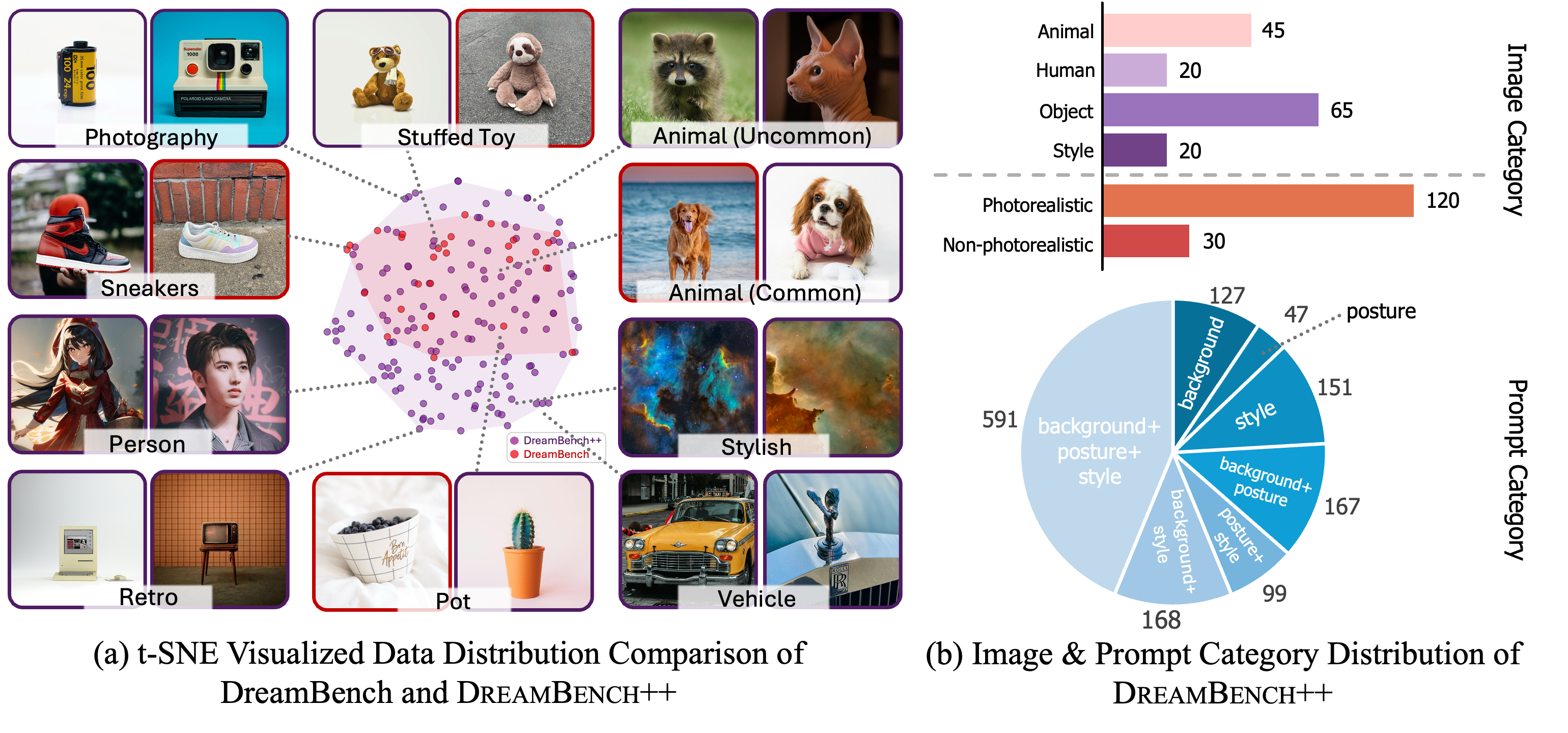
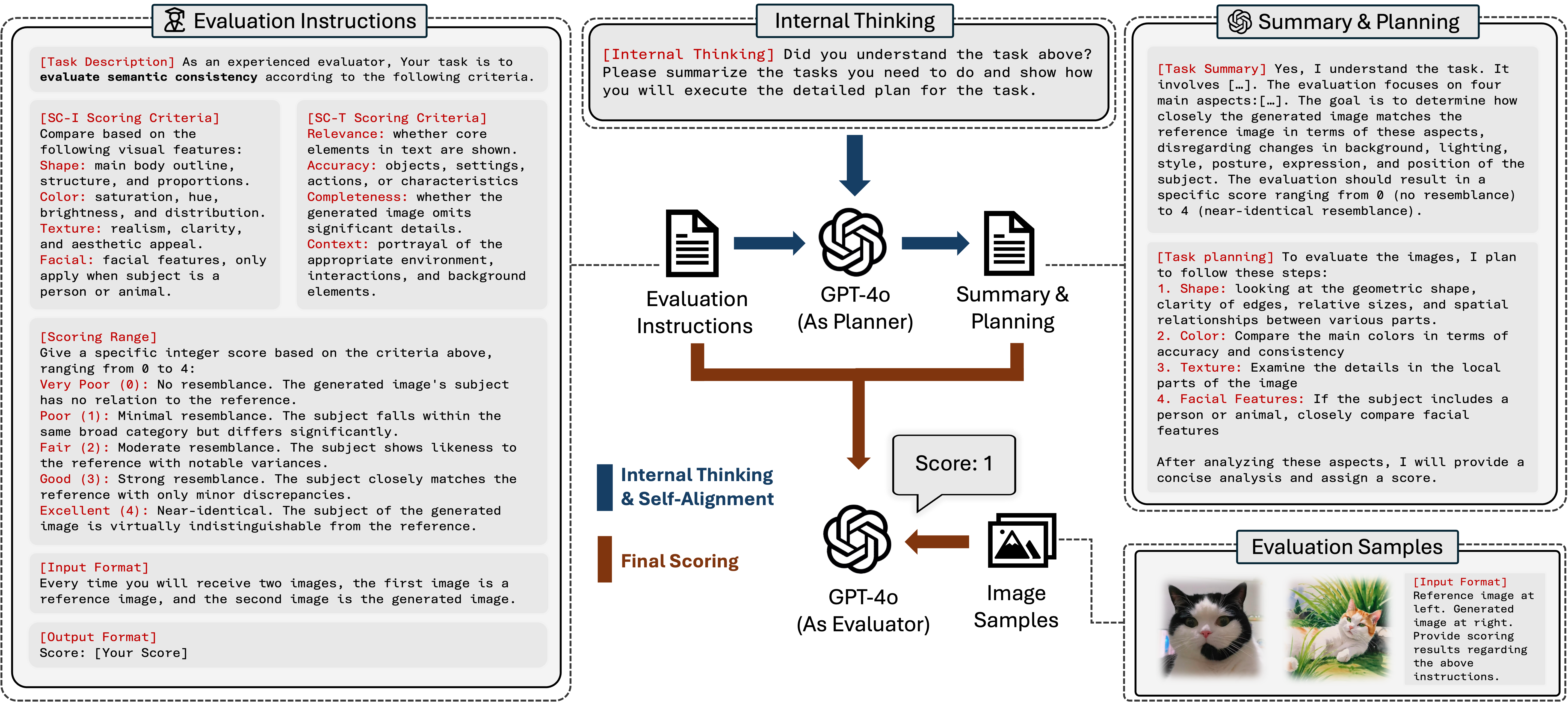
DreamBench++
A Human-Aligned Benchmark for Personalized Image Generation
ICLR 2025
1 
2 
3 
4